实验物性预测正在成为真实世界材料研发的主要瓶颈之一。
目前大多数材料基础模型在计算性质上最强:稳定性、热力学量、吸附能,以及其他可大规模生成的标签。但实际研发往往依赖测量得到的终点指标 —— 它们稀疏、嘈杂、异质,且直接关联到产品性能。这些指标包括沸点、溶解度、介电性质、输运性质、可燃极限、结合亲和力的代理指标,以及其他采集成本很高的实验测量。
Materials Property Axiom (MPA) 是一个三阶段训练框架,旨在弥合这个差距。它借鉴了在大语言模型上行之有效的训练范式 —— 广域预训练(pre-training)、对齐式中训练(mid-training)、任务特异的后训练(post-training),并将其迁移到材料物性预测。
在 40 项实验物性基准上,相比直接对预训练模型做 fine-tuning,MPA 平均把 MAE 降低约 10%,在单个分布外任务上最高降低 51%。当中训练的信号与最终 readout 与目标物性的物理本质匹配时,提升幅度最大。
MPA 已在 sciclaw.ai 上线。
为什么实验物性需要不一样的训练配方
面向分子和材料的基础模型通常从广域预训练开始,从结构、图、SMILES 字符串、3D 构象或大规模计算得到的物性中学习通用的材料表征。这让它们能作为可复用的 backbone 服务于下游预测。
这种做法成效不错,但它在模型预训练所学和工业材料研发所需之间留下了一道缺口。
不同的实验终点指标不能互换。一项热力学性质、一个偶极矩、一个水溶解度值、一项蛋白结合代理指标、一条可燃极限,各自由不同的物理机制主导。有的近似具有"原子或官能团层面的可加性",有的依赖材料的极性或电子结构,还有的由溶剂化、界面行为或识别效应主导。最重要的是,任何新材料的发明都不是只命中一个,而是同时命中多个物性目标。
MPA 背后的核心假设很朴素:
不同材料物性任务之间的迁移能力,取决于共享的物理,而不只是共享的数据统计。
也就是说,辅助训练数据不应只因为量大或好取而被选入,而应该因为它编码了与目标指标相关的物理信息而被选入。
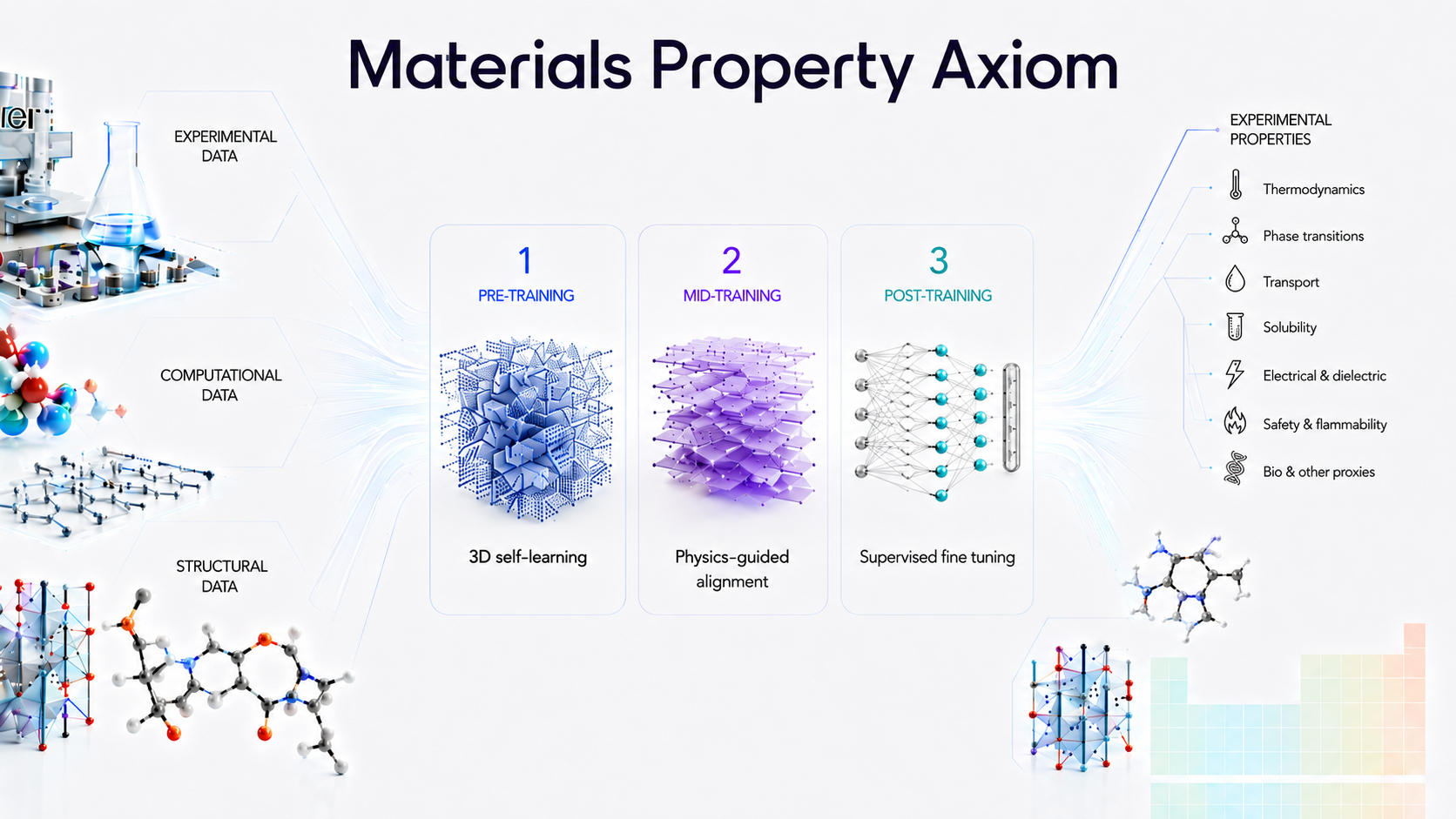
三阶段训练框架
MPA 包含三个阶段的训练:
- Pre-training(预训练): 在大规模材料几何构象语料上学习通用的 3D 表征。
- Mid-training(中训练): 用物理上相关的辅助物性标签对齐这一表征。
- Post-training(后训练): 在下游实验物性上做 fine-tune,搭配为测量数据设计的 readout 和损失函数。
Pre-training(预训练)
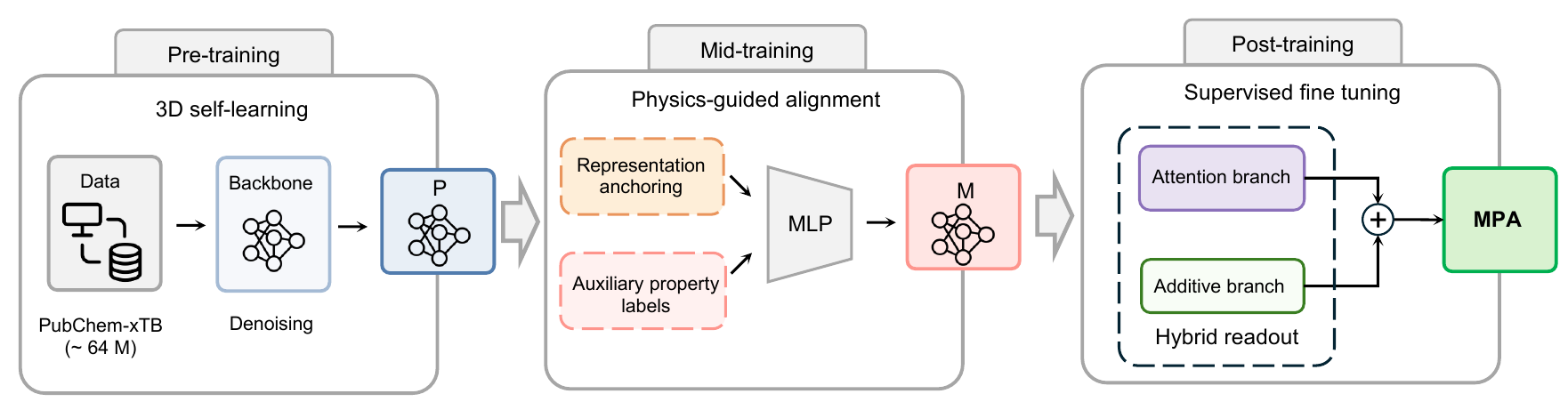
Pre-training 阶段用基于几何的 3D 自监督来初始化材料基础模型的 backbone。我们使用了由约 6400 万个优化后的材料几何构象构成的 PubChem-xTB 语料。
我们的目标不是把整个框架绑定到某一个特定的预训练模型上。Pre-trained backbone 提供的是通用的化学与空间表征。
Mid-training(中训练)
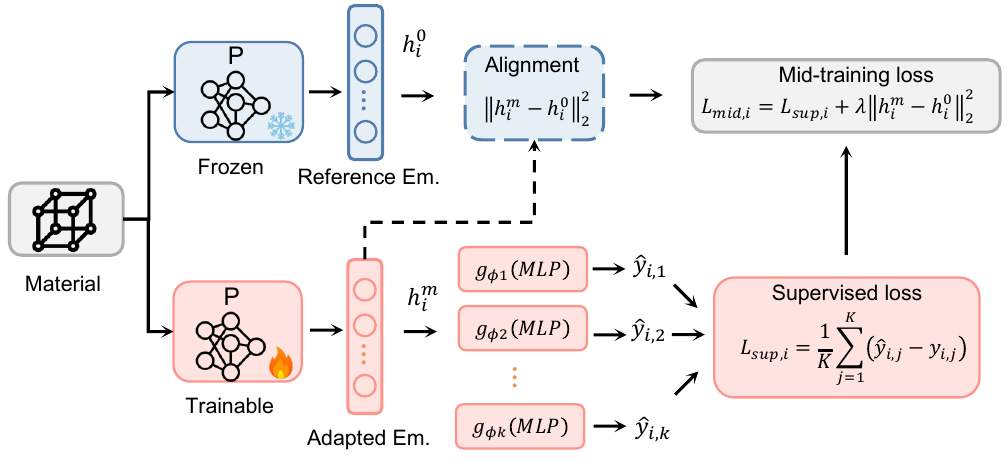
Mid-training 阶段用与下游目标物理相关的辅助标签来适配预训练好的 backbone。
我们使用了几个 mid-training 数据源:
- TCIT 热化学标签: 生成焓、Gibbs 自由能、热容、熵以及相关热化学量。
- g-xTB 电子结构标签: 偶极矩、HOMO-LUMO gap。
- 实验 logP: 围绕亲脂性的信号,与溶剂化和分配相关。
- 多源 mid-training: 同时使用热化学、电子结构、logP 监督信号的组合设定。
MPA 还会对中训练后的表征做正则化,使其不偏离原始预训练表征太远。这样 backbone 仍锚定在广域 embedding 空间里,同时能沿物理上有用的方向移动。
Post-training(后训练)
最后一阶段在每一项下游实验物性上分别对模型做 fine-tune。
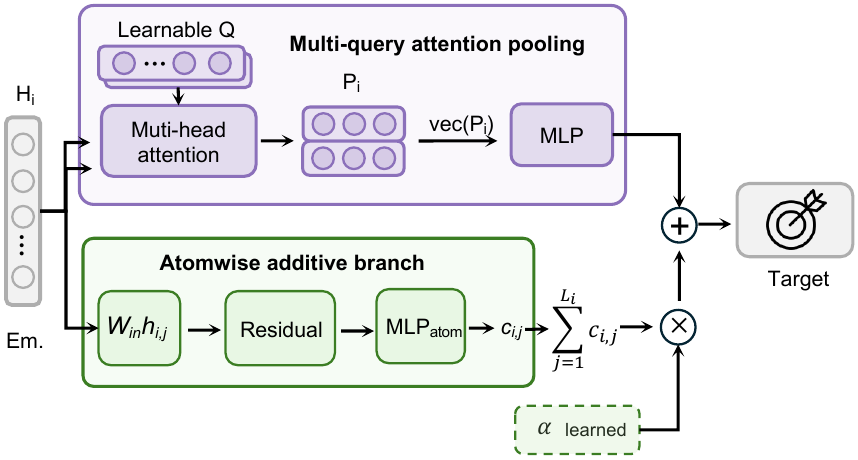
MPA 对标准 fine-tuning 配方做了两处改动:
- 用 Huber 风格的 smooth MAE 取代 MSE,使训练对重尾误差和离群点不那么敏感;
- 用"attention pooling + 原子级可加分支"的混合 readout 取代标准的 attention readout。
Attention 分支给模型提供灵活的非可加材料汇总;可加分支给模型一个显式的局部贡献先验,这对于"可以近似分解为原子级或片段级贡献"的广延性质很有用。
把"物理对齐"作为 scaling 的原则
我们发现,把多种实验物性在物理意义上对齐的 mid-training 是 MPA 成功的关键。
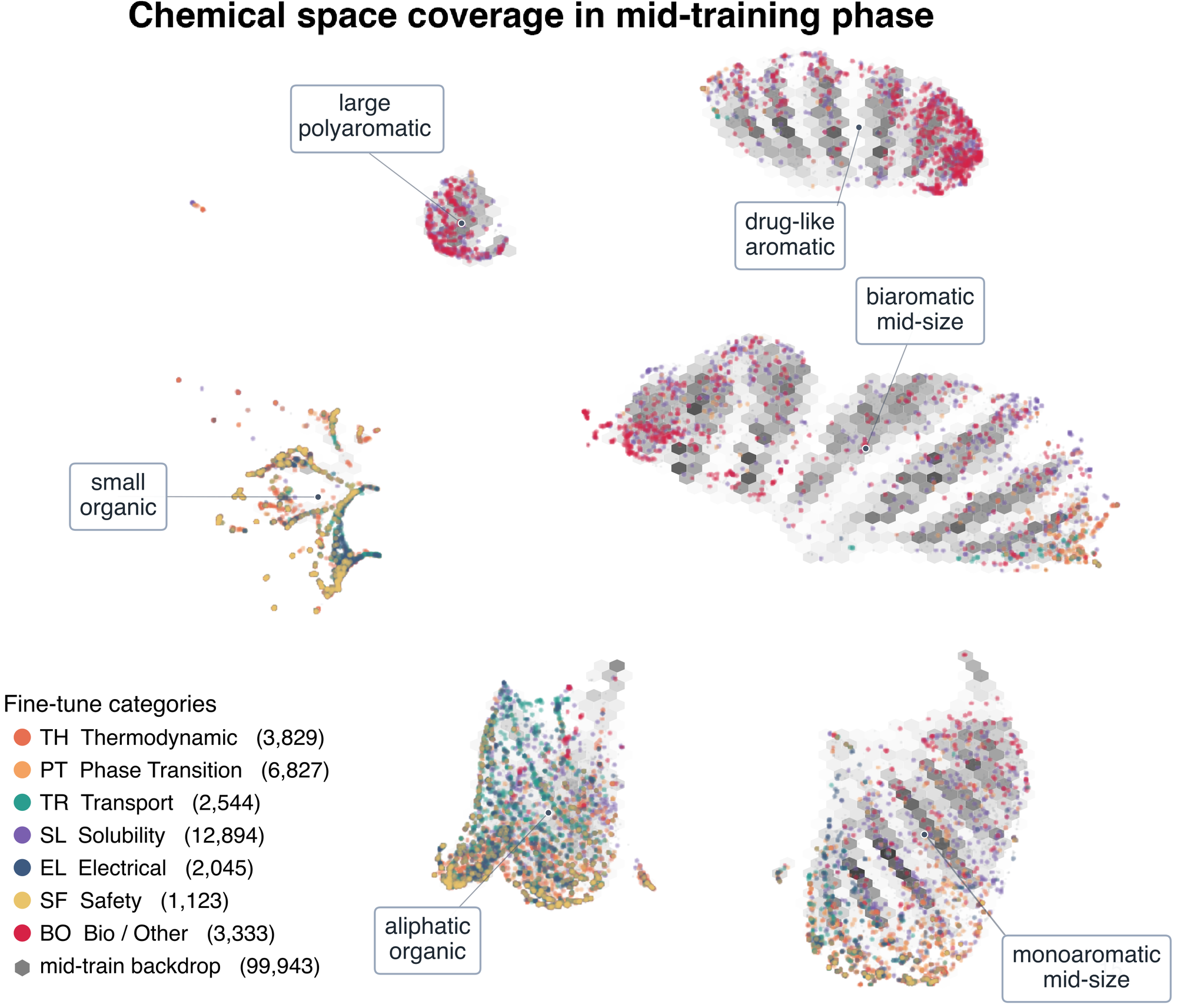
热化学的 mid-training 对热力学和相变类目标迁移最强;电子结构的 mid-training 对电学和极化类终点迁移最强;LogP 的 mid-training 对溶解度、分配以及生物/制药代理任务迁移最强。
这一规律之所以重要,是因为它让"迁移"变得可解释 —— 当辅助信号和下游终点共享物理结构时,MPA 提升最大。
同样的原则也适用于 readout 层面。可加分支在"对可加性兼容"的物性上帮助最大;当终点指标主要由识别效应、器件级行为、界面机制、或者无法干净映射成原子级求和的比值类测量主导时,这一分支帮助变小,有时甚至会拖后腿。
这给了 MPA 一条实用的设计原则:让 mid-training 的数据选择和 readout 的归纳偏置都匹配目标物性的物理本质。
在实验基准上的广泛提升
我们在一个精心整理的、涵盖 40 项实验材料物性预测任务的基准上对 MPA 做了验证,任务涉及:
- (TH) 热力学性质
- (PT) 相变类性质
- (TR) 输运性质
- (SL) 溶解度与分配性质
- (EL) 电学与极化性质
- (SF) 安全与可燃性
- (BO) 生物/其他材料物性代理指标
我们在两种互补的评估设定下对 MPA 做了考察。Random split 衡量分布内插值能力 —— 结构相关的分子和材料可能同时出现在训练集和测试集;Scaffold split 更难:它考察模型能否泛化到训练时未见过的材料骨架。
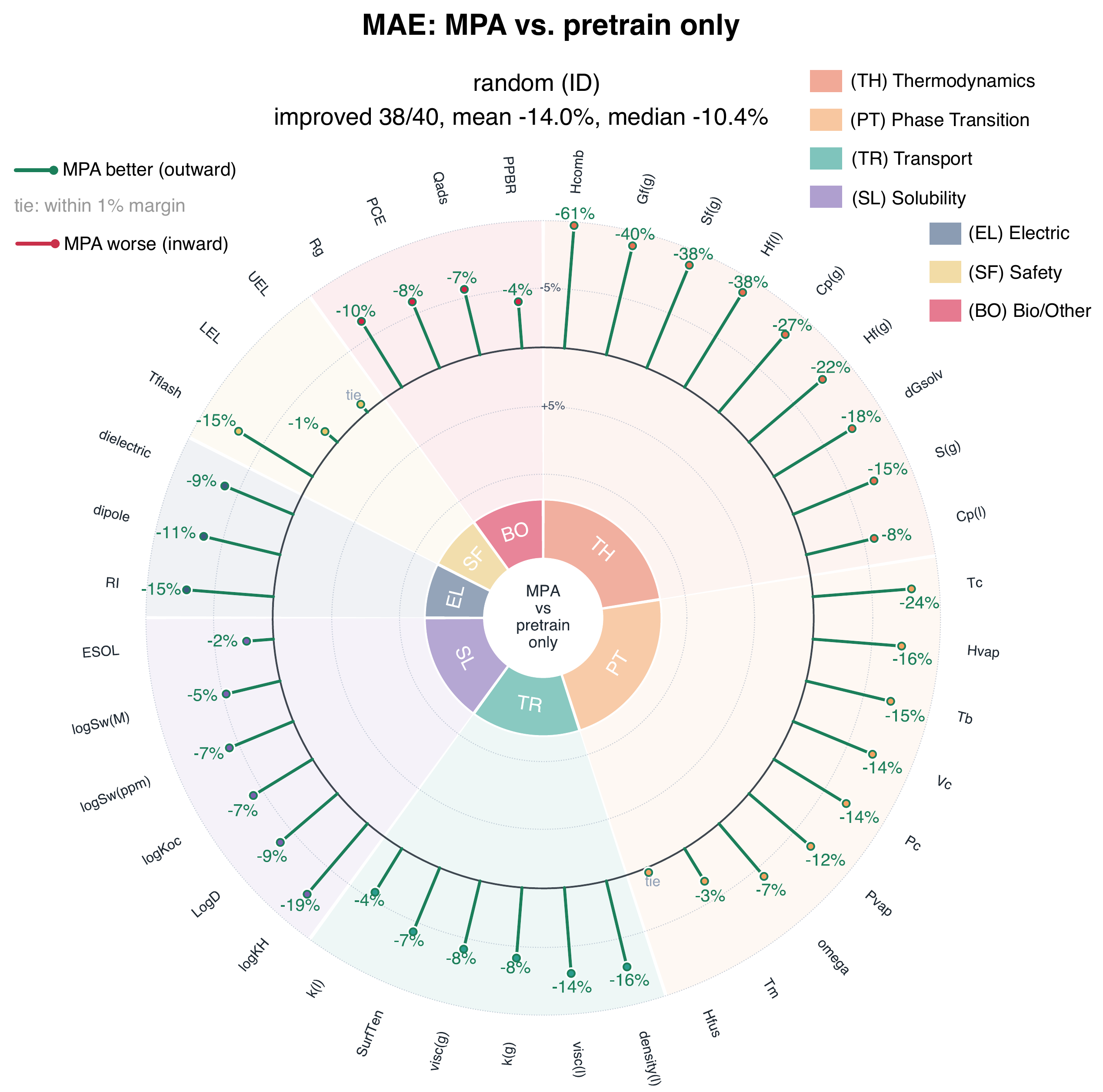
在 random-split 评估下 MPA 刷新 state of the art,几乎每一个终点指标相比直接 fine-tune 都有提升。增益并不局限于某一类物性 —— 热力学、相变、输运、溶解度、电学、安全、生物/其他终点都有提升,最大降幅出现在物理对齐的热力学目标上,如燃烧焓、气相 Gibbs 自由能、熵、液相焓、气相热容。
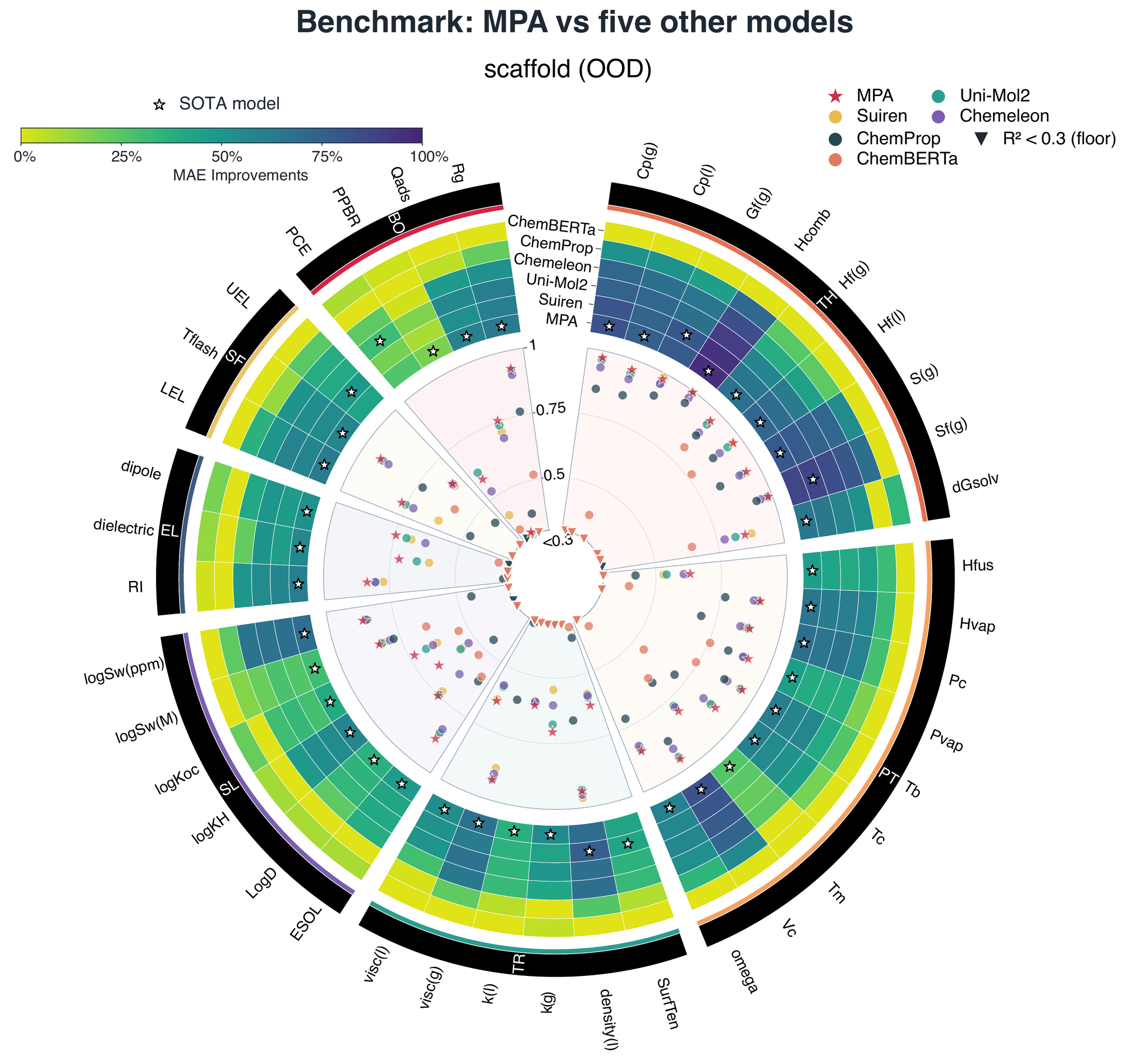
在 out-of-distribution 设定下,MPA 也在多个强基线(Suiren、Uni-Mol2、CheMeleon、ChemProp、ChemBERTa)之上刷新了 state of the art。模型在热力学、相变、输运、溶解度、电学、安全、生物/其他终点上往往拿到最佳表现。这一点很重要,因为 scaffold split 更接近真实研发场景 —— 模型必须外推到训练未见过的材料族,而不只是在近邻同类之间做插值。
这意味着什么
MPA 把材料基础模型的适配重新框定在"物理对齐"这个原则上。它提供了一条可行路径,把第一性原理计算、精选的实验数据,以及任务特异的 fine-tuning 融合进一个可扩展的训练配方里。
对化学和材料工业来说,这改变了 AI 切入研发循环的位置 —— 模型可以在合成之前就按"与产品相关的实验终点"筛选候选,可以优先决定下一批要做哪些测量,从而减少对缓慢试错迭代的依赖。随着越来越多的计算和测量数据出现,MPA 提供的是一条让这些数据沉淀为可复用预测能力(而不是一堆孤立的单任务模型)的路径。
结果是一条更系统化的路线,通向更快的配方设计、分子优化、材料发现以及面向应用的设计。一个材料基础模型的价值,不在于单纯做得更大,而在于与测量物性的物理对齐。