Experimental property prediction is becoming one of the main bottlenecks in real-world materials discovery.
Most materials foundation models are strongest on computational properties: stability, thermodynamics, adsorption energies, or other labels generated at scale. But practical discovery work often depends on measured endpoints that are sparse, noisy, heterogeneous, and directly tied to product performance. These include boiling points, solubility, dielectric properties, transport properties, flammability limits, binding proxies, and other experimental measurements that are expensive to collect.
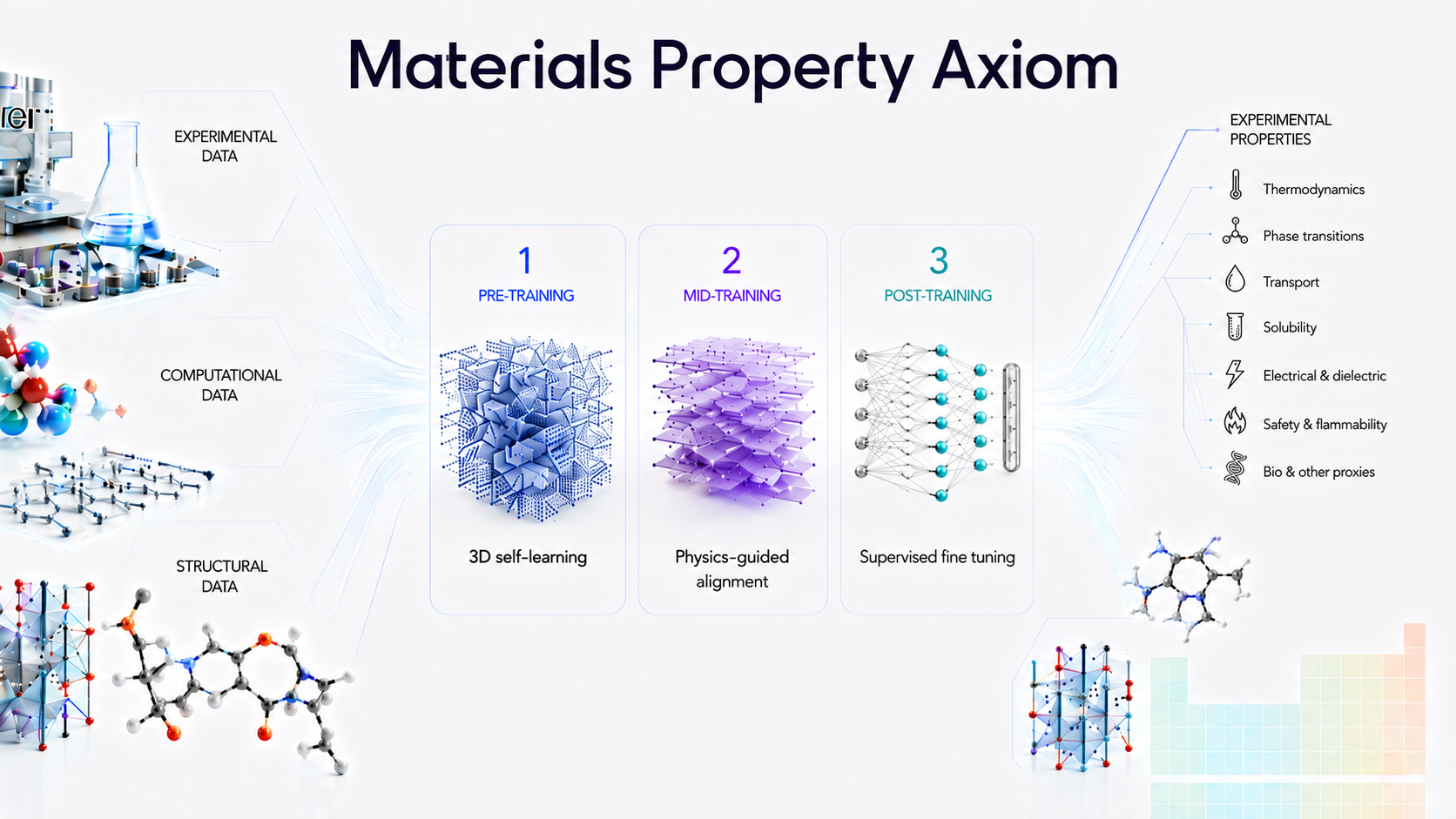
Materials Property Axiom (MPA) is a three-phase training framework designed to close that gap. It takes the training pattern that has worked for large language models—broad pre-training, aligned mid-training, and task-specific post-training—and adapts it to materials property prediction.
Across 40 experimental property, MPA improves mean absolute error by about 10% on average and by up to 51% on individual out-of-distribution tasks compared with direct fine-tuning from a pretrained model. The largest gains appear when the intermediate training signal and the final readout match the physics of the target property.
MPA is available at sciclaw.ai.
Why experimental properties need a different training recipe
Foundation models for molecules and materials usually begin with broad pre-training. They learn general materials representations from structures, graphs, SMILES strings, 3D conformations, or large-scale computed properties. This makes them reusable backbones for downstream prediction.
That approach has worked well, but it leaves a gap between what models learn during pre-training and what industrial materials discovery needs.
Experimental endpoints are not interchangeable. A thermodynamic property, a dipole moment, an aqueous solubility value, a protein-binding proxy, and a flammability limit are governed by different physical mechanisms. Some are approximately additive over atoms or functional groups. Some depend on materials polarity or electronic structure. Some are dominated by solvation, interfacial behavior, or recognition effects. Mostly importantly, the invention of any new materials need to hit targets for not one, but many properties
The core hypothesis behind MPA is simple:
Transfer across materials property tasks is governed by shared physics, not shared data statistics alone.
That means auxiliary training data should not be selected only because it is large or convenient. It should be selected because it encodes physics that is relevant to the target endpoint.
A three-phase framework
MPA went through three phases of training:
- Pre-training: Learn a general 3D representation from a large materials geometry corpus.
- Mid-training: Align the representation with physically relevant auxiliary property labels.
- Post-training: Fine-tune on downstream experimental properties with a readout and loss designed for measured data.
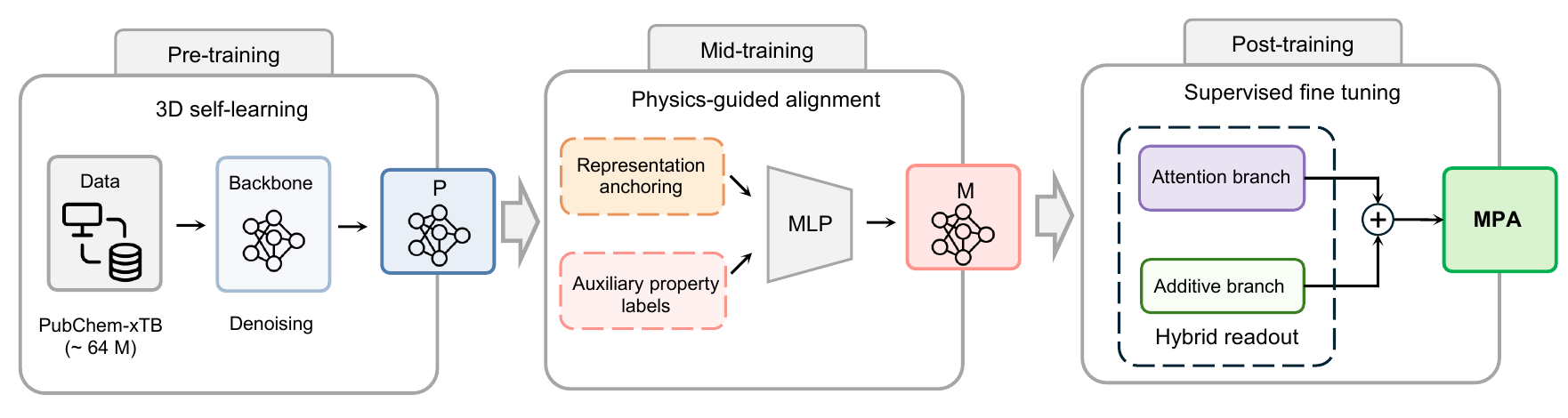
Pre-training
The pre-training stage initializes a materials foundation model backbone using geometry-based 3D self-supervision. We used a PubChem-xTB corpus built from roughly 64 million optimized materials geometries.
The goal is not to make the framework depend on one specific pretrained model. The pre-trained backbone provides a general chemical and spatial representation.
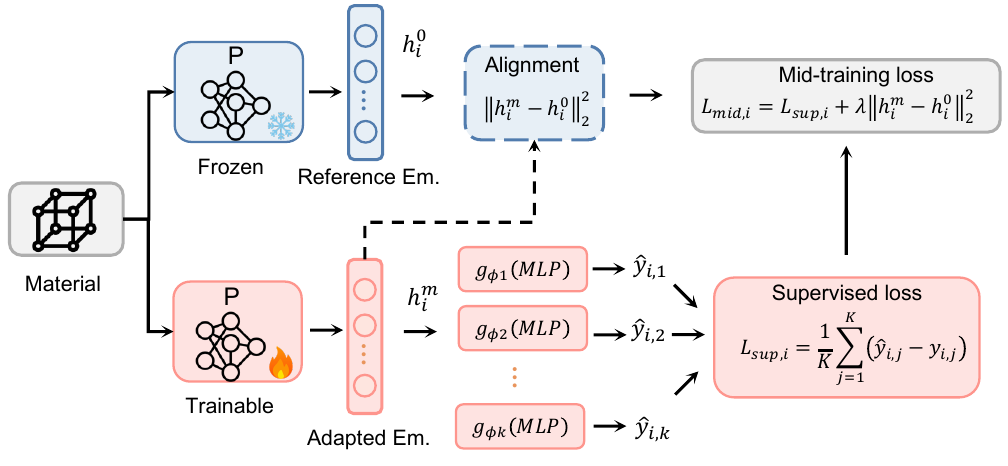
Mid-training
Mid-training adapts the pretrained backbone using auxiliary labels that are physically related to downstream targets.
We included several mid-training sources:
- TCIT thermochemistry labels: Formation enthalpy, Gibbs free energy, heat capacity, entropy, and related thermochemical quantities.
- g-xTB electronic labels: Dipole moments and HOMO-LUMO gaps.
- Experimental logP: A lipophilicity-oriented signal tied to solvation and partitioning.
- Multi-source mid-training: A combined setting using thermochemical, electronic, and logP supervision.
MPA also regularizes the mid-trained representation so it does not drift too far from the original pretrained representation. This keeps the backbone anchored in the broad embedding space while allowing it to move along physically useful directions.
Post-training
The final stage fine-tunes the model on each downstream experimental property.
MPA changes two parts of the standard fine-tuning recipe:
- It replaces mean squared error with a Huber-style smooth MAE loss, making training less sensitive to heavy-tailed errors and outliers.
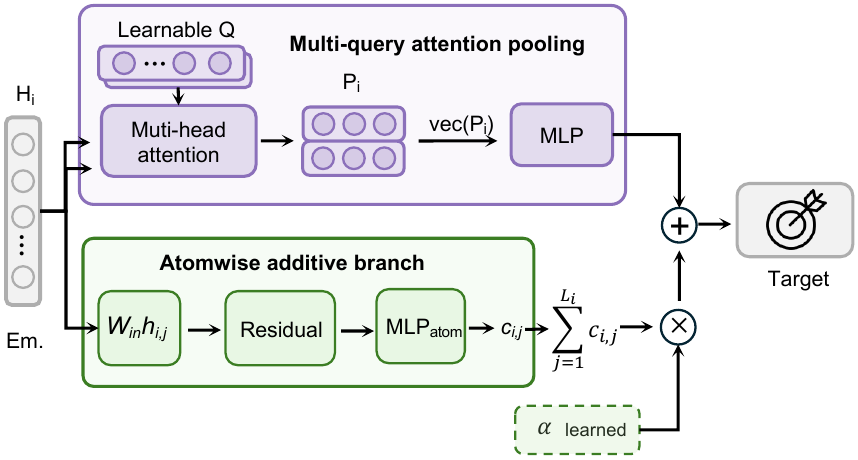
- It replaces a standard attention readout with a hybrid readout that combines attention pooling with an atom-wise additive branch.
The attention branch gives the model a flexible non-additive materials summary. The additive branch gives the model an explicit local-contribution prior, which is useful for properties that are extensive or approximately decomposable into atom-wise or fragment-level contributions.
Physical alignment as the scaling principle
We find the mid-training, which align embeddings from various experimental properties physically, is critical to the success of MPA.
Thermochemical mid-training transfers most strongly to thermodynamic and phase-transition targets. Electronic-structure mid-training transfers most strongly to electrical and polarization endpoints. LogP mid-training transfers most strongly to solubility, partitioning, and bio/pharma proxy tasks.
This pattern matters because it makes transfer interpretable. MPA improves most when the auxiliary signal and downstream endpoint share physical structure.
The same principle applies at the readout level. The additive branch helps most on properties that are additive-compatible. It helps less, and can sometimes hurt, when the endpoint is dominated by recognition, device-level behavior, interfacial mechanisms, or ratio-like measurements that do not map cleanly to an atom-wise sum.
This gives MPA a practical design rule: match both the mid-training data and the readout bias to the physics of the target.
Broad gains across experimental benchmarks
We validated MPA across a curated benchmark of 40 experimental materials property prediction tasks spanning:
- (TH) thermodynamic properties
- (PT) phase-transition properties
- (TR) transport properties
- (SL) solubility and partitioning properties
- (EL) electrical and polarization properties
- (SF) safety and flammability properties
- (BO) bio/other materials-property proxies
We evaluated MPA under two complementary settings. Random splits measure in-distribution interpolation, where structurally related molecules and materials can appear across train and test folds. Scaffold splits are harder: they measure whether the model generalizes to materials scaffolds not seen during training.
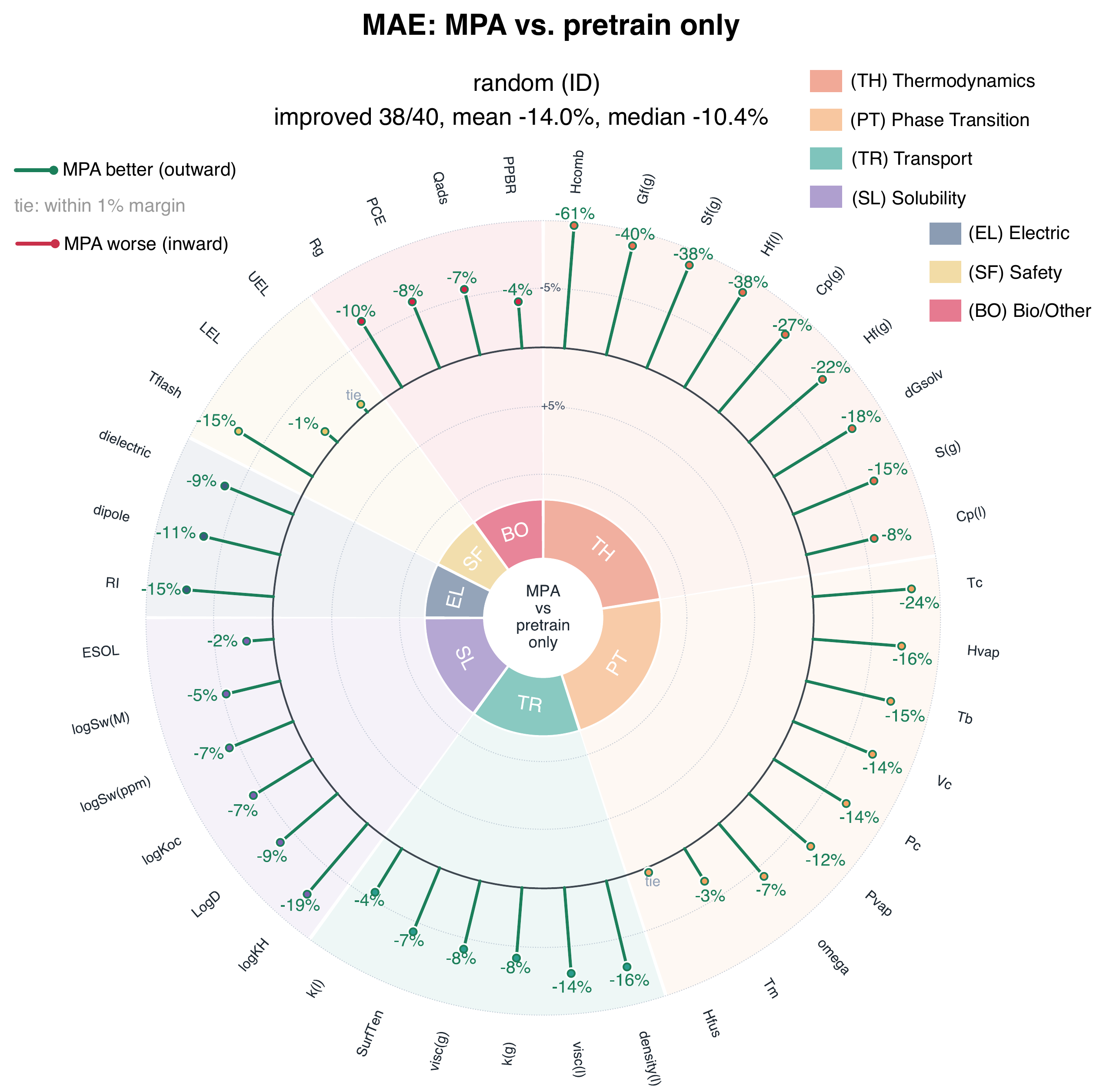
MPA sets a new state of the art under random-split evaluation while improving nearly every endpoint relative to direct fine-tuning from the pretrained backbone. The gains are not confined to one property family: thermodynamic, phase-transition, transport, solubility, electrical, safety, and bio/other endpoints all improve, with the largest reductions appearing on physically aligned thermodynamic targets such as combustion enthalpy, gas-phase Gibbs free energy, entropy, liquid-phase enthalpy, and gas-phase heat capacity.
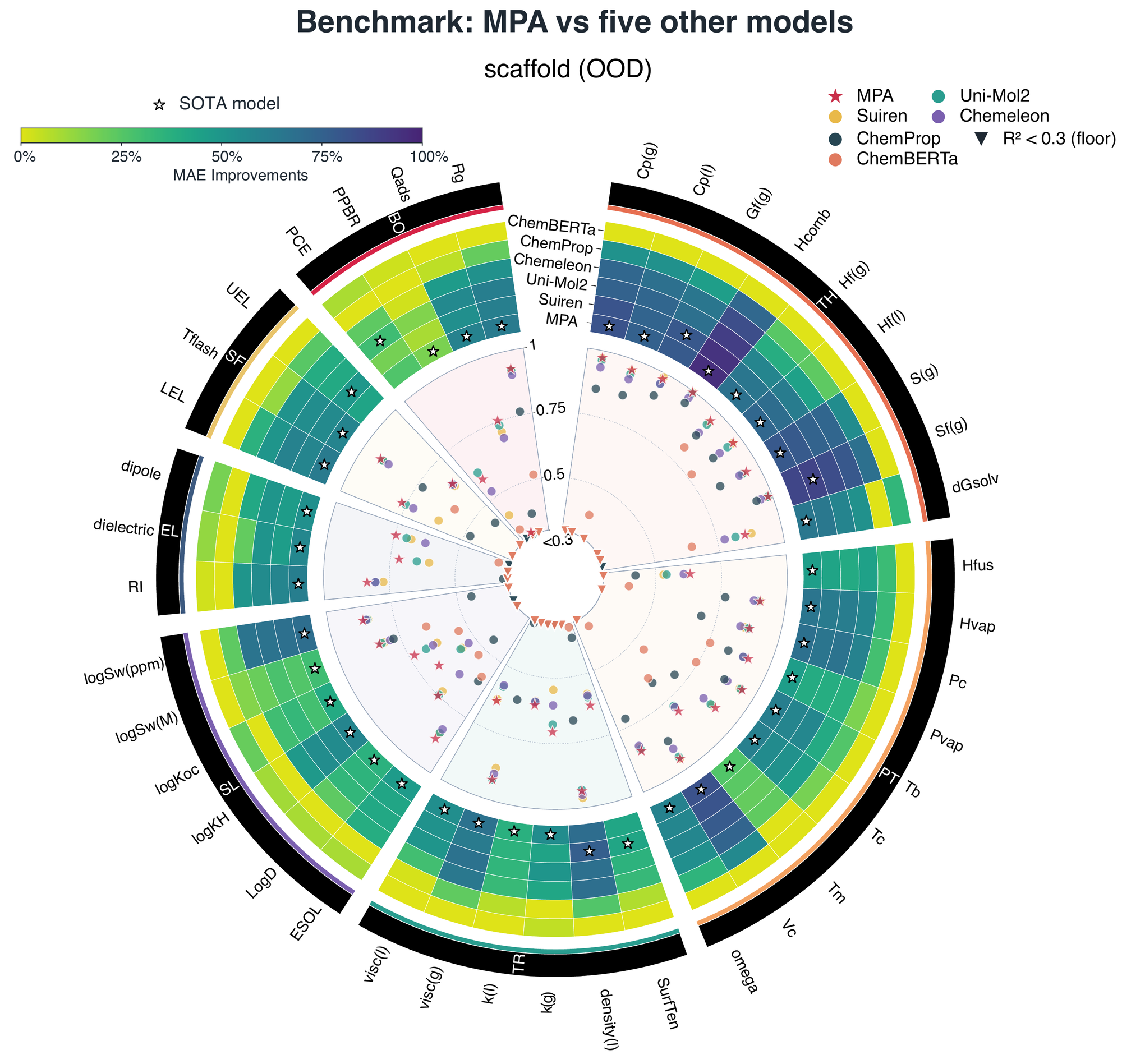
Under out of distribution shift, MPA also establishes a new state of the art against strong external baselines including Suiren, Uni-Mol2, CheMeleon, ChemProp, and ChemBERTa. The model frequently reaches the best-performing position across thermodynamic, phase-transition, transport, solubility, electrical, safety, and bio/other endpoints. This matters because scaffold splits are closer to the discovery setting, where the model must extrapolate to new materials families instead of interpolating among close analogues.
What this enables
MPA reframes materials foundation model adaptation around physical alignment. It provides a practical way to combine first-principles computation, curated experimental data, and task-specific fine-tuning into one scalable training recipe.
For the chemistry and materials industry, this changes where AI can enter the discovery cycle. Models can screen candidates against product-relevant experimental endpoints before synthesis, prioritize which measurements to run next, and reduce reliance on slow trial-and-error iteration. As more computed and measured data become available, MPA offers a path for turning that data into reusable predictive capability rather than isolated task-specific models.
The result is a more systematic route to faster formulation, molecule optimization, materials discovery, and application-driven design. A materials foundation model becomes valuable not simply by being larger, but by being aligned with the physics of measured properties.